
Coding Period 7 (24th July - 6th Aug)
In continuation with the problems with the version-1 of our model (which was getting 11% BLEU accuracy), I discussed the output with mentors. After a day or two of error analysis, we realised that there were few trivial problems with our dataset, due to which our BLEU score was so low:
- Double spaces: We found that there were double spaces in our dataset, and this may cause the neural network to learn different embeddings for each of the space; causing extra confusion for the NMT model.
- URIs with () paranthesis: Some of the URIs have ‘(‘ but since we encode ‘(‘, ‘)’ in SPARQL differently - for cases like order by(
) than that in NLQs - cases which contains entities like "dbr_Kalinga_(province)". These two paranthesis are being encoded, but in NLQs parathesis are a part of URI and need not be encoded (URIs should be as it is).
There were a few minor problems: such as some NLQs just did not made sense were noisy - for which we can keep a threshold frequency, but we chose to not do it right now.
After solving the above two troubles, we were good to prepare data and train the version-2 of our model. We both were hoping we get far better than mere 11%, because we guessed that “1” should be the major problem.
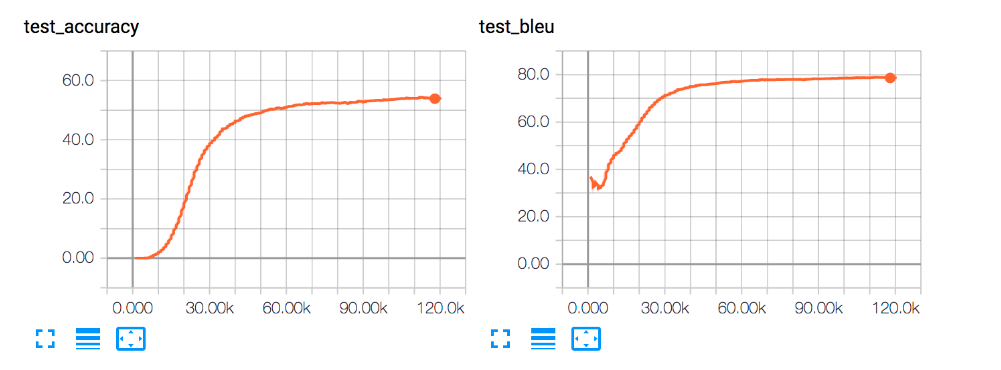
After again a wait of 9 hours, we got ~80% BLUE accuracy for our model and this marked the correctness and completeness of the project.
Training Setup and Graph Analysis:
- We generated a dataset with 44k examples of NLQ-SPARQL, and distributed our data as 8:1:1 (train:dev:test).
- As the graph shows, we reach ~75% accuracy in just 40k epochs and the model convergence to 80% in the remaining 80k epochs.
- BLEU score signifies the quality of our translation. It compares our model’s target language translation with the expected SPARQL for the NLQ. 80% values means that our translation’s quality is 0.8 times the quality of an SPARQL expert.
- The test accuracy as the name suggests that around 60% of our NLQ queries exactly match with the required target SPARQL translation.
Error Analysis:
- The major accuracy error occurs due to wrong entity mapping.
- There are still a lot of noisy properties in our dataset, which lead to bad translation - this can be improved by chosing a threshold over number of occurrences of each property and choosing only those which occur often in the training and testing data.
This marks the end of a end-to-end system which generates dataset automatically for NSpM learner.
Compositionality Experiment:
With nearly two and a half week until the final deadline of GSoC tenure, we decided to try a ML experiment to test whether a machine learning model can learn compositionality. Precisely, the goal of this experiment is as follows: The goal is to train a model on data {‘a1’, …, ‘an’, ‘b’, ‘a1○b’, …, ‘an○b’, ‘c’,’d’} and test on data {‘c○d’}. The idea is to check whether the Neural MT model can learn how to translate composite NLQ queries into SPARQL by learning on other composite NLQ-SPARQL examples.
For starters, me and my mentors mutually decided to perform our experiment on a simpler setting, where ‘d’ is equal to ‘b’.
Setting 1:
Train a model on data {‘a1’, …, ‘an’, ‘b’, ‘a1○b’, …, ‘an○b’, ‘c’} and test on data {‘c○b’}.
For Instance, the data would look something like this:
Trainset:
a1 := “what is the county of
b := “where is
a1○b := “where is the [county] of
…
an := “what is the region of
an○b := “where is the [region] of
c := “what is the district of
Testset:
c○b := “where is the district of
During our meeting on how to generate this dataset, we saw that the atomic queries (both NLQ and SPARQL) can be automatically constructed using my project’s tool. One thing to notice, to be able to form composite query, say(ai○b), we would have to choose only such a[i]’s which have a rdf:range as class Place or a subset of class Place.
Now consider the composite templates - SPARQL query templates for them could be easily generated (just we have to design a composite query such as : “SELECT ?a WHERE { http://dbpedia.org/ontology/county ?b . ?b http://dbpedia.org/ontology/location ?a }”).
NLQ templates for composite queries become tricky. On little observation, we could devise a pattern to generate them too.
During the last day of this period, I had started to write scripts to generate composite templates from our Gold Standard.