
Final Week: Coding Period 8 (7th Aug - 14th Aug)
After completing the required scripts to fetch all the templates and testing their correctness, I was ready to generate the train and test data for the composition idea.
The generation of train and test set for this experiment was a little different from the scripts I had been using. The subtle difference is that, the test set will include c○b template, which should not be seen in the train set. So, I had to create two annotations separately for train and test data namely - annotations_composite_train.csv, annotations_composite_test.csv, where the test.csv had only 2 composite out of 18 (so that test data ~10%).
I completed with the data generation using the generator.py script on those templates. Our first version of setting 1 of composite templates is ready for testing!
After the data was generated and I shared with Tommaso too, we found that there was some ambiguity between the generator query templates (SGQs). Like we had discussed, there were two generator query templates identical in semantics but syntactically different.
For instance, SGQ for *where is the [county] of
- SELECT ?a WHERE {
<http://dbpedia.org/ontology/county> ?x . ?x <http://dbpedia.org/ontology/location> ?a } - SELECT ?a WHERE {
<http://dbpedia.org/ontology/county> [ <http://dbpedia.org/ontology/location> ?a ] } - where we simply reduce the variable ?x.
In our first dataset, there were ambiguity because of using a mixture of both of them - how would the model know that 1 and 2 are same. So, we chose to stick to only 1 type queries.
I re-generated the data and we were good to go for the training step.
Our v1 training results did not look good:
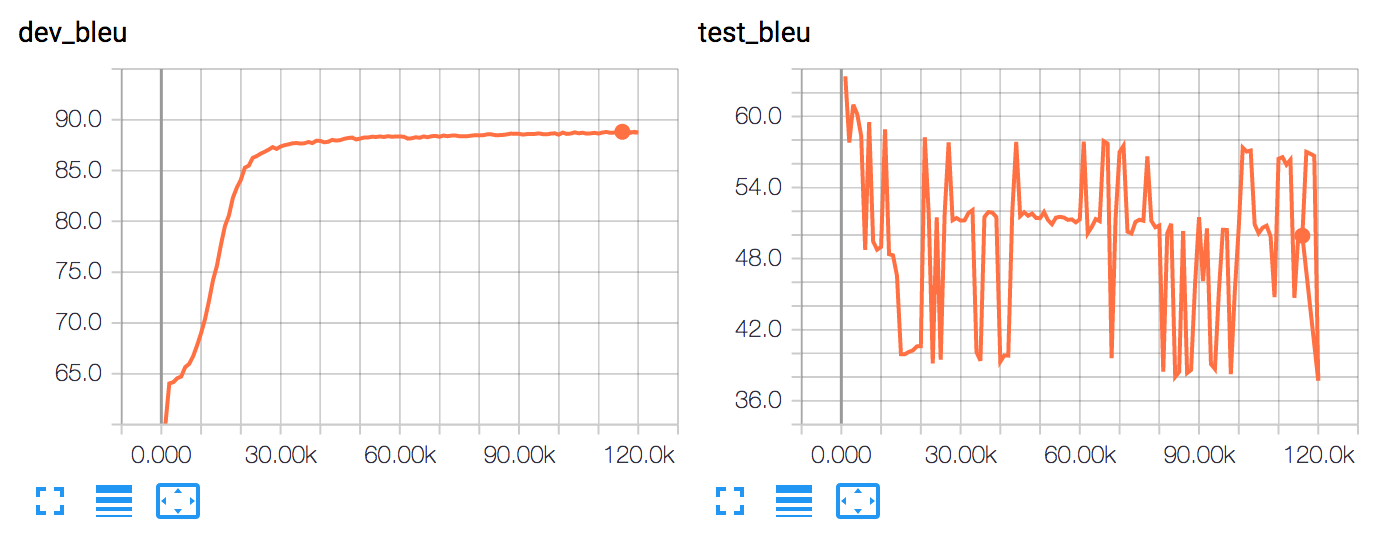
The test accuracy was surprisingly 0.0 meaning that none of our expected output in SPARQL matched with the correct translation. The idea and also the experiment itself are at a very initial stage - so there was no trouble of having a low accuracy or low bleu score, but 0.0? Furthermore, the zig-zag pattern in the test_bleu with increasing #epochs should not happen. There had to be something wrong.
I re-used some previous analysis scripts and built one more to analyse the mistakes. As per the results 100% test error was because of wrong entity mapping between the required translation and our output translation. This looked strange. I built another script to find out how many entities in the test queries were previously seen in the training data - the result was 0/1200. Voila, since the all the test entities were unseen in the training data, our NMT is not able to properly map any of the test entities.
After looking closely, we found that the intersection of test and train vocab (of entities) was NULL. Also, we found that when there’s a single annotation file for train and test, the entities used to generate data for each template uses a common set of entites. So, the next step was to generate a common annotation file for both train and test data set - name annotations_composite_common.csv.
Even after generating data using a common template file, there were many cases where the test query entities were absent in training - we decided to remove them for now.
Following the above settings, we had 463 rows in the test dataset. And soon we began with training of v2 of Setting 1. The accuracy was still low, but not zero! So, we did successfully experiment the composition idea too during the GSoC tenure :).
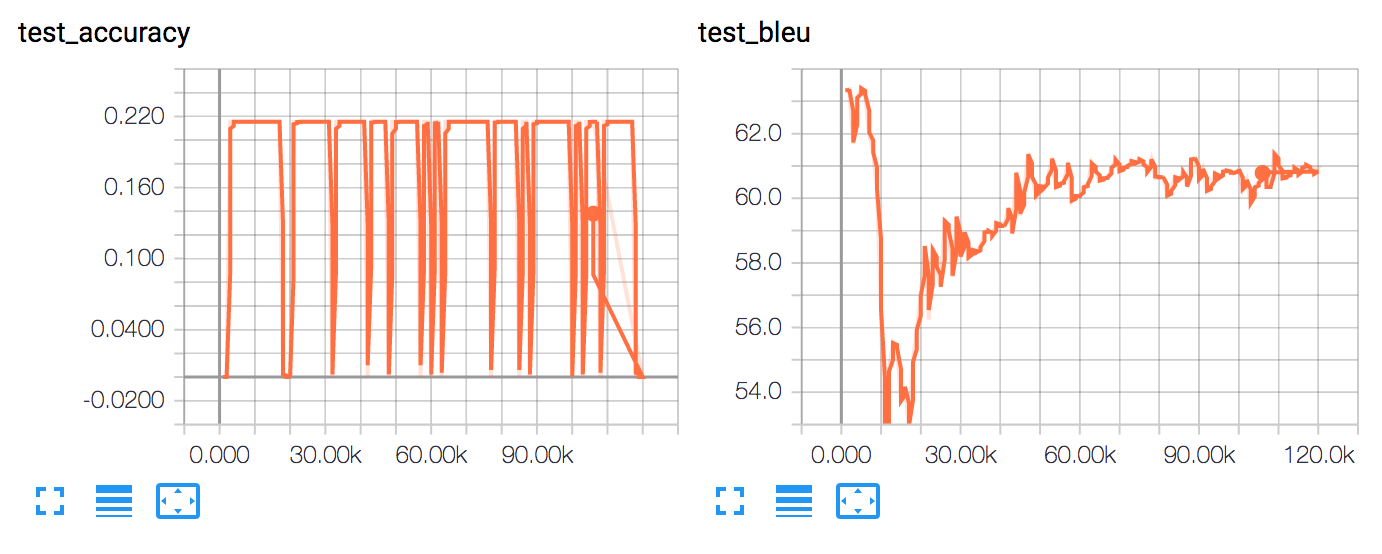
The zig-zag pattern in the test_bleu has also disappreared in this version which further explains the success.
This experiment marked the end of my GSoC tenure, officially. Me, Tommaso and Dr. Ricardo are hoping to continue with this research idea beyond the GSoC and hope to further closely learn about automatic compositionality learning idea.
That’s all from my Google Summer of Project with DBpedia. It was an awesome experience to work with the DBpedia community.
Cheers! :)